
(原标题:英伟达下一个“大杀器”)鬼父2
今天这个料有点猛,GB200、GB300、VR200之后,英伟达还在筹谋什么?如下图(from 肉总)
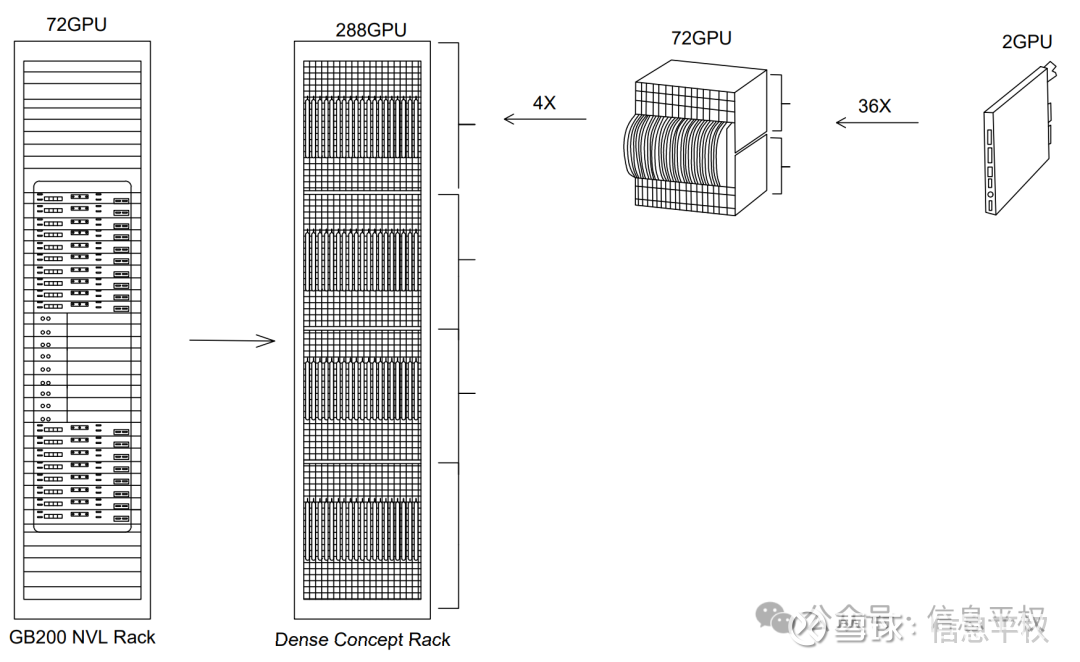
其实颠倒于,将4个NVL72赓续压缩成一个288卡单机柜。这里有太多道理的点值得咀嚼:
1. 我第一反馈是,这玩意靠谱吗?问了止境服气的一位好意思国年老,他之前就参与过IBM大型机研发,其时GB200出来他提议了许多狞恶的问题。他看完这个288卡“怪物”居然认为,make sense...因为模子责任负载的重点变了...
2. 什么样的负载?彰着是推理。教诲期间,后向传播需要超大范畴的模子并行,从而强调大集群、机柜间互联(inter-rack);而推理,尤其是小模子、多步推理,强调的不是大集群,而是局部强互联,或者“超节点”(intra-rack)。之前著述也曾说过,HBM措置了访存带宽最高性价比,而本钱、能耗更低的铜缆杀青的超节点,措置了单机柜内卡间互联最高性价比,从而大幅裁汰推理本钱(从pre-fill和decode两个推理的进度来看,推理本钱的内容是带宽本钱)。从最近模子发达来看(尤其是o1),NV这种超节点大机柜确切界说的相当精确。
3. 其次,铜缆的生命周期可能比念念象中长。这不是光和铜谁替代谁的问题,而是AI卑劣责任负载挪动的问题...任何产业王人会从研发走向“坐蓐部署”,而推理占据90%以上负载可能仅仅本领问题。而推理更强调局部互联,说到底,铜缆是刻下低本钱、低功耗、高踏实性地杀青局部互联的最好款式。因此无谓连络Rubin还用无谓铜缆,铜缆可能会握续许多代。黄仁勋2天前和ARM CEO有个播客建议巨匠去听,其中提到一句:“尽可能长本领的使用铜/电传输,从而裁汰本钱和复杂性”
4. 之前8机柜576卡互联的问题赢得了解答。之前按照GB200机柜之间的距离,用无源铜缆连续是不成能的。而按照这个暗示图,颠倒于把NVL72机柜进一步压缩,机柜之间的距离,拉到了以致 1 米以内,也即是无源铜缆不错隐藏的距离,从而杀青了L1层聚积全铜连续。而铜缆不错杀青的NVLink domain,从72膨大到了288,关键问题来了,这需要一个超强的交换机,没错,是个288 High radix switch...
5. 散热如何措置...这可能是我最大的疑问。毕竟当今NVL72的散热就搞了好久..而图中这个估量打算,确切是100%水冷,但288卡塞到一个rack(暂时不知谈这是几许U或者多高的机柜),如故难以念念象。其次,这个单机柜功耗是1MW...什么主意,刻下GB200是120kw,照旧需要新建IDC,那么1MW…这里画一个大大的问号。
6.系统踏实性如何?若是此次GB200遭逢的问题最终措置(散热、铜缆、cowos-L),有可能给Vera Rubin以及这个288卡“怪物”铺平了路。从Blackwell此次的delay不错看到,芯片每年一迭代的难度是极大的,但在软件和系统层面每年作念优化却不详许多,通过board level的集成杀青性能飞跃,可能确切是更恰当的一条路。
7. 最贫窭的问题,这玩意,不错再把推理本钱裁汰几许?不知谈订价、精度等因子,若是只看单机柜的性能perf,不错相当粗造的筹备,288卡、单卡假定4颗die、NVlink假定至少翻倍、HBM也至少翻倍,总计机柜的性能应该是GB200的至少30倍...而从perf/W的角度,能够莳植了4倍的能耗后果。因此,回到咱们那句老话,英伟达是“因”而不是“果”,是NV在鼓动行业的卓绝,将o1这种reasoning model的本钱再裁汰一个数目级,maybe不错让愚弄的出生更快少许...
8. 终末,回来下将来3年的英伟达居品线:2025H1行业大范畴部署GB200,2025H2部署GB300/GB300A,2026部署Rubin系列的VR200,2026年底或者2027部署这个288卡的“Rubin-Next”。将来3年推理本钱下落弧线明晰可见。
终末要声明,图中所示,isearly concept to illustrate direction, not final design”,即NV的早期估量打算主意。不外刻下看下来,相对靠谱,相宜下一步推理负载的演进趋势,也依然延续着NV“系统性能数目级莳植”的老路。GB200高强度拉练了一遍供应链,快速扫清了茫茫多工程阻截,之后“系统压缩”这条路可能也相对顺畅一些。
喜爱夜蒲(完)